Machine Learning Competition
Overview
ENPH 353 is a project course designed to teach machine learning techinques with an end-of-term competition. The premise of the competition is to develop algorithms that allow a simulated robot to traverse a parking lot and correctly identify locations and number plates of parked cars while avoiding pedestrians and a moving vehicle. The simulation took place in Gazebo in ROS
The Competition
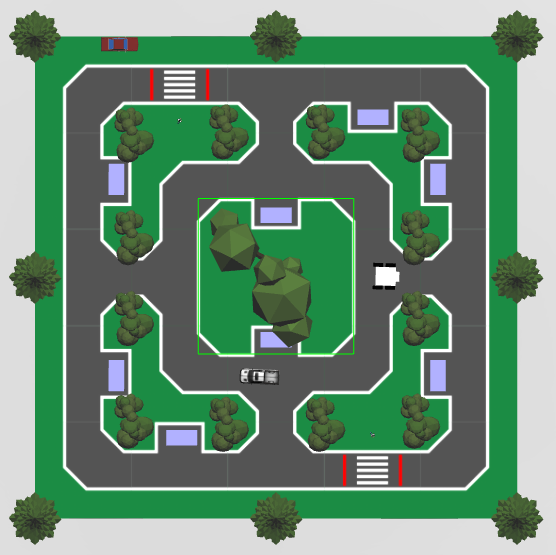
The image above shows the parking lot for the competition. The robot is the white, square car. It’s task is to drive on the roads while collecting the license plates on the blue rectangular cars. Additionally, it must avoid pedestrians and the truck driving around the inside track.

The license plates hold two pieces of information, the position of the car marked with the larger P1 above, and a BC auto-generated license plate with two letters and two numbers.
The inputs to the system were the images captured by a camera mounted on the robot’s frame and as outputs the robot would publish velociy commands to guide the robot as well as positions and license plate data to a server for scoring.
The scores are determined by the following:
| Rules | Points |
|---|---|
| Correctly record license plate and position for a car on outside track | +6 |
| Correctly record license plate and position for a car on inside track | +8 |
| More than two wheels outside of the track | -2 |
| Collide with white pick-up truck | -5 |
| Hit pedestrian | -10 |
| Drive one full loop around the outer track | +5 |
The Strategy
YOLO
I decided to use the YOLO framework to allow the robot to understand it’s environment. Yolo stands for “You Only Look Once”, and is a state of the art object detection system. I used YOLOv3 to obtain labeled bounding boxes around classes of interest, namely the blue parked cars, pedestrians, the truck, and license plates.
YOLO works by taking an image and dividing into smaller subsections, and predicting locations and accuracies for bounding boxes of a certain class. The advantage of using YOLO is that it is incredibly fast compared to other classifier models, allowing us to obtain near real-time predictions.
Training the model required around 200 labeled images taken from simulation video, trained for about 25000 iterations. In ROS, a node subscribes to the camera feed and passes the images through yolo. A YoloElement message was made to store each bounding box for each class, and publish it to a yolo node. This node informs pedestrian logic and gives bounding boxes for the license plate detection as well.

Navigation
The main components of the robot’s navigation are the driver and controller.
Driver
The essential method for Karen’s driving was get_twist(). This method used computer vision techniques to return a Twist command (Twist is a message that contains all the velocities of the robot) which would be called by the controller to drive the robot. The driver has three main approaches to following the road.
The first two approaches are very similar. The robot can follow the road by either looking at the right edge or the left edge of the road and following it. These approaches are mirror, so the following is a list of steps taken to perform right edge following:
- Scale input image to a smaller size and apply HSV mask to filter out the road.
- Find the first pixel of a road from the right-hand side at an upper and lower location.
- Compare these pixel locations to the expected locations to determine the current error.
- If the error magnitude exceeds a threshold, turn left if the error is negative, or right if the error is positive, otherwise, drive straight.


This method was found to be robust. Even when starting off the road, the robot will turn and navigate towards the road, and begin following the edge. However, general navigation and knowing which way to drive is not solved by this approach. The controller must solve these challenges. Note, to follow the left edge, the white lines are flipped about the y-axis in the above figures.
The third approach of road following is to use the “center of mass” of the road. This method is not as robust as the above edge following. However, this approach is necessary when the edges of the road are misleading. This approach follows a similar idea as edge following, except it differs in steps 2 and 3:
- Threshold the image so that the road is a binary mask.
- Use OpenCV to compute the moments of the image, then compare the x coordinate of the center of mass of the road with the center of the image to get the error.
In general, each of these approaches could follow the road successfully. It is up to the controller to decide when to use each approach.
Controller
The robot’s controller makes decisions about when and where to turn, when to stop for pedestrians, and when to stop for the pick-up truck. The following is a flow chart illustrating the state diagram of the controller:
Position and License Plate Recognition
License Plates
The algorithm takes cropped license plate images based on bounding box predictions from YOLO and does some preprocessing before passing them into a CNN for character recognition.
The preprocessing algorithm takes bounding boxes from /yolo with the license plate class and crops the raw camera image to size. We obtain potential characters using and adaptive threshold followed by cv2’s findContours() function. After some filtering based on size and aspect ratio, we end up with four predictions. The ordering of characters is determined based on the x position of the bounding box prediction.

Position
To read the positions of each license plate, a region of interest is defined based on the bounding box around the license plate from YOLO. To perform character recognition, the CNN is used again, trained on data collected from allowing the robot to do several laps around the perimeter.

Results
A total of 20 teams competed in this competition. This model was one of four to receive a perfect score of 57 points.
The video above shows the robot completing the outer ring. The Gazebo simulation is shown on the right, the scoring server is on the bottom left, and the terminal displaying information about the robot is on the upper left.
Francisco Farinha
Data Scientist @ BlackBerry
Interested in solving real-world problems using Machine Learning techniques.